2023. 4. 16. 15:38ㆍPython(파이썬) 공부
파이썬으로 많은 데이터들을 보기 쉽게 정리해서 시각화 해보도록 하자!
우선 데이터를 가져와서 그 데이터를 기반으로 보아야 하기 때문에
공신력이 있는 자료를 가져오는 것이 중요하다!
나는 owid(https://ourworldindata.org/coronavirus)에서 데이터를 받아와서 사용했다.
사이트에 접속해보면 Download Dataset이 보일것이다.

클릭 하면 깃허브사이트로 넘어가는데 밑으로 조금만 내리다 보면
Download our complete COVID-19 dataset 옆에 CSV | XLSX | JSON 이 보인다.
여기서 CSV파일을 다운했다.
이제 이 파일의 경로를 내가 공부하는 폴더로 옮겨줄것이다.
일단 다운로드 파일로 가서 받은 csv 파일을 복사해서

내가 공부하고 있는 파일로 바로 옮겨줬다.
이유는 경로 지정할 때 착오가 없게 하기 위해 바로 붙여넣었다.
이제 데이터도 받아왔으니 실습을 해보자!
우선 데이터 분석을 위해 pandas 라이브러리를 임포트 하고
csv 파일을 불러오자!

pandas 라이브러리의 read_csv()를 이용해 방금 받아온 파일을 읽어들였다.
읽어들인 데이터는 데이터프레임 타입으로 저장된다.
먼저 데이터프레임 정보를 info()함수를 통해 확인해보자!

총 67개의 칼럼들이 나왔다.
이제 데이터를 확인할 것인데, 간단하게 일부 데이터를 확인하는 방법인
head() - 상위 5개 데이터 확인, tail() - 하위 5개 데이터 확인
함수들을 사용해 보자!
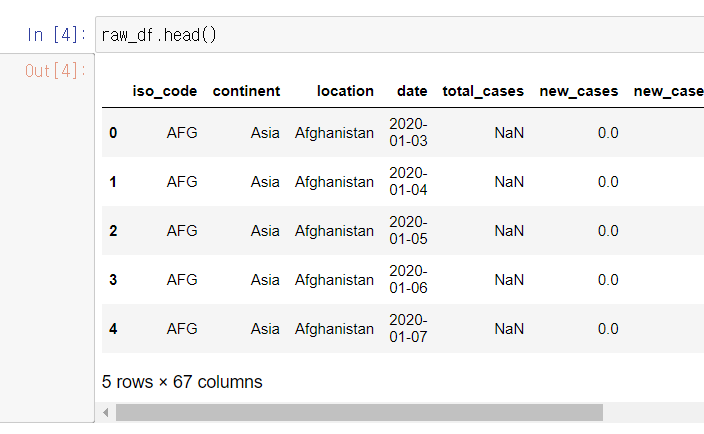

보기 좋은 표로 데이터들을 확인 할 수 있다
그런데 칼럼 수가 67개나 있기때문에 쓸모 없는 데이터들을 없애고 싶다.
이번엔 원하는 열 리스트를 만들어 필터링한 데이터 프레임을 생성해보자!
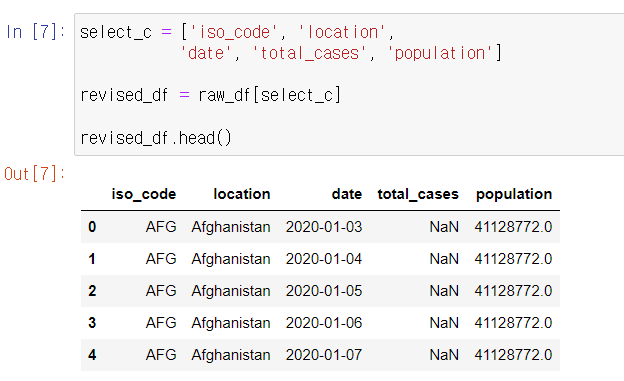
원하는 열 이름을 리스트에 담아 새로운 데이터 프레임에 저장했더니
내가 원했던 정보들만 출력해주는 데이터 프레임이 생성됐다!
이번엔 원하는 국가의 데이터만 추출한 데이터 프레임을 생성해보자!
일단 여기서 국가를 뜻하는 location의 값을 확인해보자
동일한 국가 이름이 중복되어 표시되는걸 알 수 있다.
이제 데이터에 있는 나라 이름을 하나씩만 출력하려면
데이터의 유일 값을 출력해주는 unique() 함수를 쓰면 된다!

이제 내가 원하는 국가의 데이터명을 찾아보자!
나는 한국과 미국을 알아볼것이다.
한국 = South Korea, 미국 United States
먼저 대한민국 데이터만 추출한 데이터프레임을 생성 할 것이다.

location열의 데이터가 South Korea 인 데이터만 가져올 수 있었다
인덱스 번호가 거슬린다.. 날짜를 인덱스 대신으로 보여줄 수 있을 것 같다.

set_index함수를 이용해 날짜를 인덱스로 설정했더니 훨씬 보기 좋아졌다!
이제 똑같은 방법으로 미국의 데이터도 받아오자!

이번엔 확진자 수만 따로 가져와서 그래프를 그려보자!
total_cases 열의 데이터만 가져와서 시리즈를 생성했다.

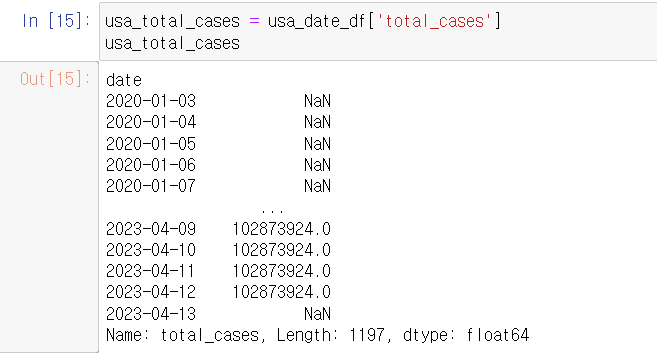
이제 두 시리즈를 합쳐 그래프를 그릴 데이터프레임을 생성하자!

칼럼명을 KOR, USA로 정하고 index번호를 위에서 만든 날짜순 데이터프레임을 이용해
설정해줬더니 깔끔한 데이터프레임이 완성 되었다.
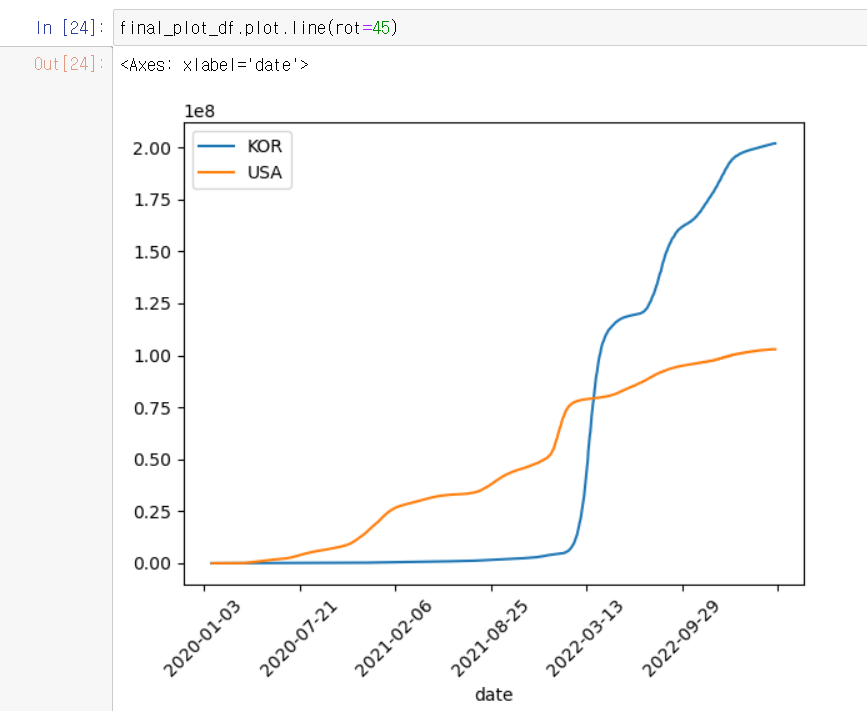
이제 plot이라는 시각화 메서드를 사용해 그래프를 그릴건데 꺾은선그래프로 보여주자

한눈에 알아보기 쉬운 그래프가 완성되었다!
그런데! 날짜가 곂쳐 보이는것도 아쉽고 최근 데이터만 가져와서 보고싶다면
슬라이싱을 해서 가져올 수 있다!

일단 날짜가 곂쳐보이는 것은line() 메서드에 속성 rot를 쓰면 되는데 반시계 방향으로 돌아간다.
그리고 2022-01-01 부터 슬라이싱해 가져온것을 볼 수 있다.
하지만 이렇게 데이터를 가져와도 의미가 크게 없는것 같다는 생각이 들었고
인구 비율당 확진자 수를 비교하고 싶다.
우리가 가져온 csv 파일에는 population라는 칼럼이 존재한걸 알 수 있다.
인구를 일단 가져와보자

그래프를 2022-01-01 부터 그릴 것이기 때문에 그 날의 인구를 가져와서 비율을 구해보도록 하자
파이썬의 round함수를 이용해 소숫점 2째짜리수 까지만 보여주도록 했다.

이렇게 비율을 구할 수 있었다!
이제 비율을 적용한 최종 데이터프레임을 만들어 보자

한국 비율을 미국과 같게 하기위해 위에서 구한 rate값을 곱해서 적용해줬다.
이제 이 데이터 프레임을 통해 꺾은선 그래프로 시각화 해보자
아까 위에서 봤던 그래프들과 다르게 비율을 수정해보니 한국의 확진자 비율이 더 크다는것을 알 수 있다.
변화가 컸던 2022년 부터 다시 그래프를 그려보자
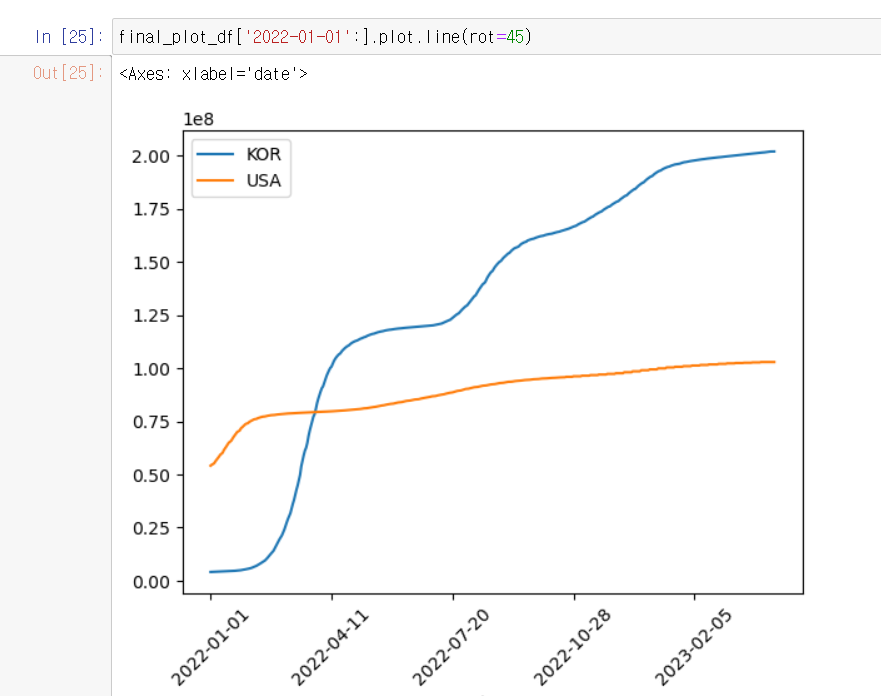
이렇게 실습을 해봤는데 필요한 데이터만 끌고와서 데이터를 분석 하니까
원하는 정보를 시각화하여 편하게 알 수 있었고 다른 곳에서도 많이 활용할 수 있을 것 같다.
'Python(파이썬) 공부' 카테고리의 다른 글
| 파이썬 openCV 라이브러리를 사용해보자1 (0) | 2023.04.18 |
|---|---|
| 파이썬 실습 2 (개발자 현황 분석) (0) | 2023.04.16 |
| 파이썬 Pandas 라이브러리를 사용해보자 (0) | 2023.04.15 |
| 파이썬 numpy 사용해보기 (0) | 2023.04.15 |
| 파이썬 기초 5(자료형) (0) | 2023.04.15 |